Practical Steps to a Comprehensive Backup Strategy – With Template
Introduction
We all rely on data to help us get our job done and enhance our life. Think of business documents, personal pictures, source code for software projects, tax receipts or health records. Some of this data now lives in the cloud. You can sync your pictures or keep your source code on Github. This has left many of us with the impression that someone else is responsible for keeping our data safe.
Since you are reading this, you probably know better. Cloud accounts can be blocked or compromised. Syncing something is not a backup, because deletions are synced as well. Even well-run data centers can burn down.1 That’s why backups are still important if you have any kind of data that’s important. Just consider this: if file or folder X was gone. Would it bother you? Could you still do your job effectively? If the answer is yes for any data you keep on your Macbook, then read on.
Having a structured backup strategy will not just save your precious family pictures, but also ensure business continuity. This article has a list of practical steps and generic templates you can use to make this task as simple as possible.
Goals
After completing the steps in this article, you will have the following:
- A list of your data assets.
- Where they are located and how they are backed up.
- Identified common errors regarding backup correlations, security and frequency.
Backups vs. Archives
This article will mainly discuss Backups, rather than Archives. The main difference between the two:
- Backups are a copy of production data that’s frequently updated without changing the source data. Main challenge is to keep up with changing source data and restore quickly if needed.
- Archives are generally accessed less frequently and the source data is deleted after creating the archive. E.g. tape storage with old accounting data. Main challenge is longevity of the data medium.
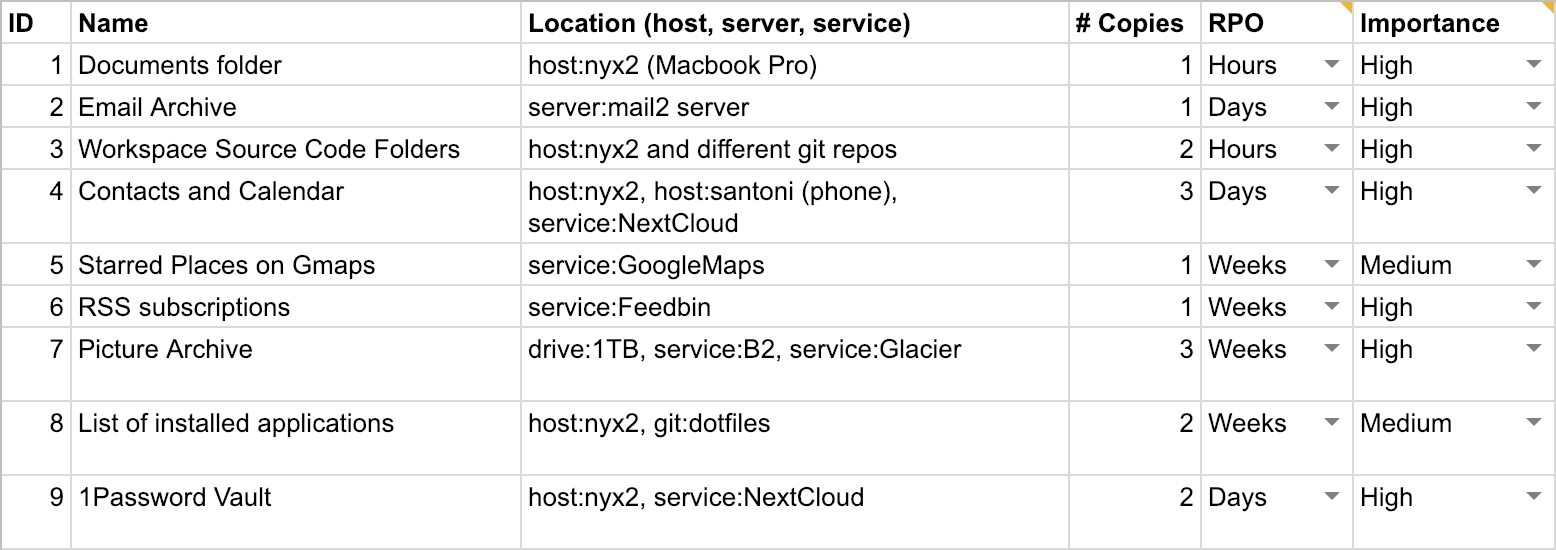
Step 1 – Inventory of Data Assets
A data asset is anything that’s digital and that has value to you. This includes individual files, as well as data stored in databases or some other means. Data assets will have different value to you. Losing baby pictures and your client database will be more severe than losing your WhatsApp chat history.
When dealing with data and backups, it’s also common to specify a Recovery Point Objective (RPO)2 for them. RPO is the data you are willing to lose because the backup was outdated. It distills the velocity of the data (how fast data changes) and the effort needed to produce it into a single parameter. For some data, like sensor readings, it may be impossible to recreate them later.
In addition you will assign the importance of each data asset. High: you never want to lose this data; medium: losing this data would be costly and inconvenient, but not terrible; low: losing this data wouldn’t have a big impact.
Try to be comprehensive when making this list. Be sure to include items that are often overlooked, like:
- Settings and data locked in applications (e.g. browser bookmarks)
- Data stored in cloud services
- Data used by employees or partners
You can use the following template3 to make your own data asset inventory. Once you’re happy with it continue with step 2.
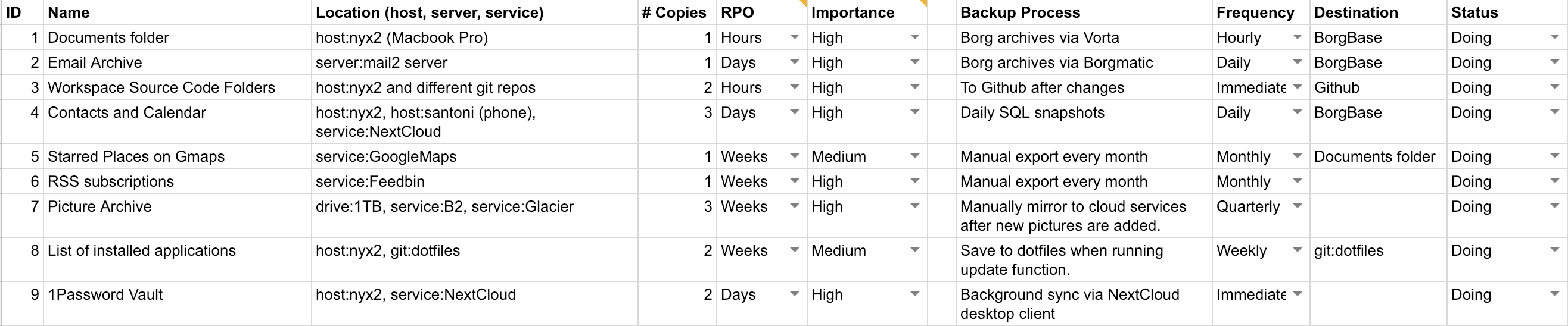
Step 2 – Selection of Backup Method
With all your essential data inventoried, you can now continue to select an appropriate backup method for each. Depending on the kind of data, data velocity and your desired RPO, some popular options for backup methods are:
- regular snapshots on the same machine (e.g. Git or ZFS)
- classic incremental backups (e.g. Borg or Time Machine)
- file sync (e.g. Dropbox or Nextcloud)
- manual data export (often necessary for cloud services)
In addition to the backup method, we will also record the frequency and destination. For automated backup processes, it’s common to do them whenever data is changed, daily or hourly. For manual data exports, you will probably do it monthly or every quarter.
Here’s an expanded version of our template3:
Step 3 – Evaluate Backup Strategy
You now have a full list of your data assets, where they live, how they change and how often they are backed up. Now we want to make sure those strategies actually protect the data by going through some data loss scenarios. These are designed to
- Show unwanted correlations between data locations (e.g. having all the data in the same physical location)
- Show insufficient backup processes (e.g. bad files being synced and the good ones deleted, permission issues).
- Find mismatches between RPO and backup frequency.
- Find Security exposures (e.g. exposed backups of confidential files)
Evaluating these issues takes some experience and technical know-how. In a corporate environment, you may need to ask colleagues for more information.
Unwanted Correlations
Probabilities of failure are usually not independent. This is frequently overlooked. Some examples of risk correlations:
- Drives of the same manufacturer tend to fail at the same time.
- Someone dropping your NAS will destroy all the drives in it.
- A fire in your office tends to burn all devices equally and at the same time.
- A rogue employee could get access to multiple machines and cloud services.
With this in mind, have another look at the template. Specifically the Location and Backup Destination columns. The former should tell you where data lives while it’s in normal use. The latter is just for backups. Sometimes this distinction is not clear cut. When in doubt use the Location column.
Once your data- and backup locations are all noted down, look for unwanted correlations in each row. If you discover correlated locations, you may need to add another backup.
Insufficient Backup Processes and Permissions
Users often assume that a file sync (Dropbox, Nextcloud) is the same as having a backup. In many cases this is not the case. Especially if the remote side doesn’t keep different old versions. To be safe against threats like cryptolockers and compromised servers, you need to ensure that the current backup process is in fact producing a data copy that is independent of the original. If a threat in one data location can easily affect the backup, then you don’t have a backup. Some examples:
- For servers, the primary server can’t have access to the backup. Else a compromise of the primary server could also destroy the backup. E.g. a hacker controlling your primary server shouldn’t be able to delete your backup.
- For sync-based data, like contact, calendards, Dropbox and others: These are NOT backups. If you accidentially delete an important contact, the deletion will be synced.
- Your employees are required to save all documents to a central file server. If there are no further snapshots or backups of those files, then this practice will only protect agains some threats (failed desktop hard drive), but not others (rogue employee deleting files on the server).
Backup Frequency Mismatch
You probably noticed this while writing up your inventory. In some cases the velocity of the data (how often it changes) will not match your current backup frequency. That means you can expect to lose more data than specified in the RPO. So for each row make sure that the backup frequency is higher or the same as the specified RPO. If it’s not, either find a way to increase it or change your RPO. Here’s an example:
An employee works on a file the whole day, but backups only happen once a day at night. If the file is damaged in the afternoon you lose one day’s work. In this case you may need to consider local snapshots or do more frequent backups.
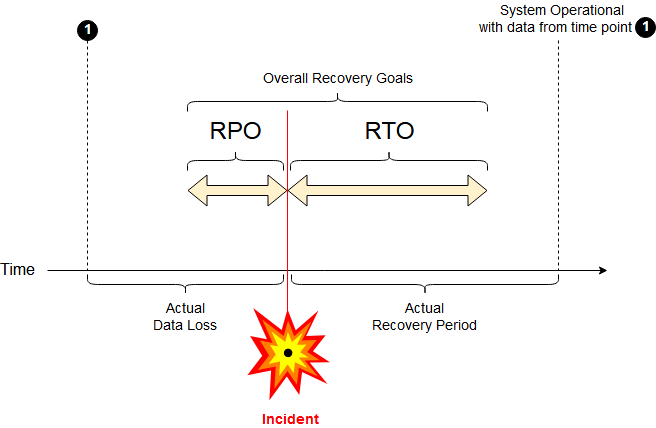
The next concept to be aware of is Recovery Time Objective (RTO). It describes the time it takes to restore the data and have a service up and running again. Restoring backup from a local hard drive would be very fast, while restoring it from slower storage, like AWS glacier would take days.4
{kind=link}
Security Issues
The data you handle will have value to other people. A competitior could be interested in documents and client lists. An employee could be interested in salary data. At the same time the fines for data breaches have been increasing. So it should be in your interest to keep all data locations safe. This includes backup locations.
For a full security review, one would also record the confidentiality and integrity requirements for each data asset. This is outside our scope. We will do a more general check for each asset to see if the locations are secure enough. For each inventory row consider the following:
- Who has access to this location? Both physical and logical. File servers should be locked and secured. Laptop drives should be encrypted.
- Is it operationally possible to encrypt the data or backup? Who has the keys?
- Correlations (again): Are you using 2-factor authentication to protect essential accounts if passwords are leaked?
Number of copies
A recommended strategy is 3-2-15, meaning 3 copies of important data – two local, one remote. In most cases this is a good number, but can’t be applied 1:1 to e.g. servers. Be aware that a RAID setup would not count as two copies6, as they are too closely related and prone to simultaneous deletion by e.g. the same logical error or malfunctioning hardware.
Conclusion
Hopefully this article was able to change your perspective7 on backups and the main aspects surrounding them. If you followed all the steps, you are in a good place now. Knowing one’s data assets, where they are located and how they are backed up is an excellent first step. Be sure to regularly update this document, as new assets are added or processes change.
For a backup solution that alleviates many of the discussed issues, consider testing BorgBase.com. It was built to solve many common backup problems:
- Append-only Backups: Compromised servers can’t change old backups.
- Encryption: Offsite backups are secure.
- 2-Factor Authentication: Protect backup repositories and settings with more than just a password.
It comes with 10 GB of backup space for free forever and is still affordable beyond that. We also offer custom solutions to enterprise customers. This includes setting up local backup agents or evaluating your whole backup strategy. Contact hello@borgbase.com for more.
Resources
-
OVH, a major French cloud provider had a fire in 2021. ↩
-
Are you ABSOLUTELY clear on your Disaster, Backup & Recovery RTO, RPO and MTO? ↩
-
See Wikipedia on Business Continuity ↩
-
Some principles are well explained in Tao of Backup ↩